

How AI videos work
An introduction for regular people

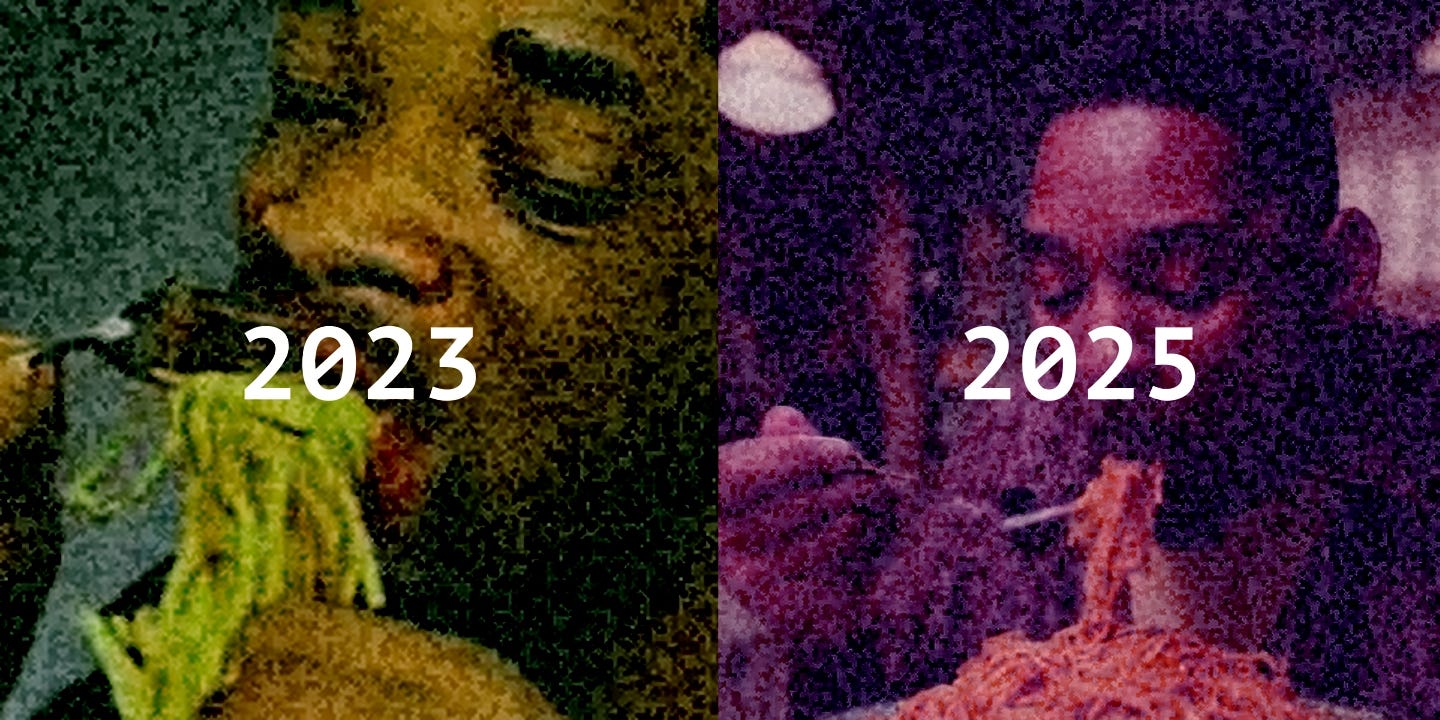
Most people have no idea how AI videos work, even though they’re everywhere. We have daily access to cameras, which we use intuitively without thinking about their underlying technology. All types of cameras, from the most “complex” cinema cameras to the one on your phone, are using the same basic principles. But AI video is completely different, because it’s not a video capture technology. It’s a video generation technology.
In real videos, a digital sensor, or traditional film, captures light bouncing off a physical environment. AI video models use complex mathematical representations to generate new pixels. This generative process is fundamentally confusing, even to the makers of these models.
Luckily, it’s not necessary to understand AI video generation at an advanced level. An imperfect, simplified understanding is enough for almost everyone, and more important than ever, now that AI literacy is so essential.
So, let me introduce you to the basics of AI video generation. I’ll just cover what’s needed for spotting patterns and understanding where we are in the AI video timeline.
What does AI mean, anyway?
AI, or Artificial Intelligence, refers to computer systems that can perform tasks we associate with human intelligence. But today, it’s a broad label for technologies that use machine learning. There are different types of machine learning systems trained on various types of data. The objective is to find patterns and make predictions. In this sense, the “intelligence” isn’t human-like intelligence, but very advanced pattern prediction.
The best-known type of AI today is probably the large language model, or LLM. That’s what powers ChatGPT, Claude, Gemini, and many others. LLMs are trained to learn patterns in text data so they can generate text later. The biggest LLMs are called “frontier models,” which run on huge clusters of computers in data centers.
Other forms of AI are smaller in scope and can run locally on your devices. Your phone’s autocorrect is basically a tiny language model. It predicts the next word, but it does that with much less context and computation, so most people wouldn’t call that “AI” today. The opposite is also true, though: a lot has been rebranded to “AI” because it’s a buzzword. AI means different things to different people.
Making AI media
A video is a series of still images that are stitched together very quickly, one after another, to simulate motion. Video cameras capture these images, known as “frames” in video, with a sensor. Animation works similarly, but frames are either drawn by hand or rendered by a computer.
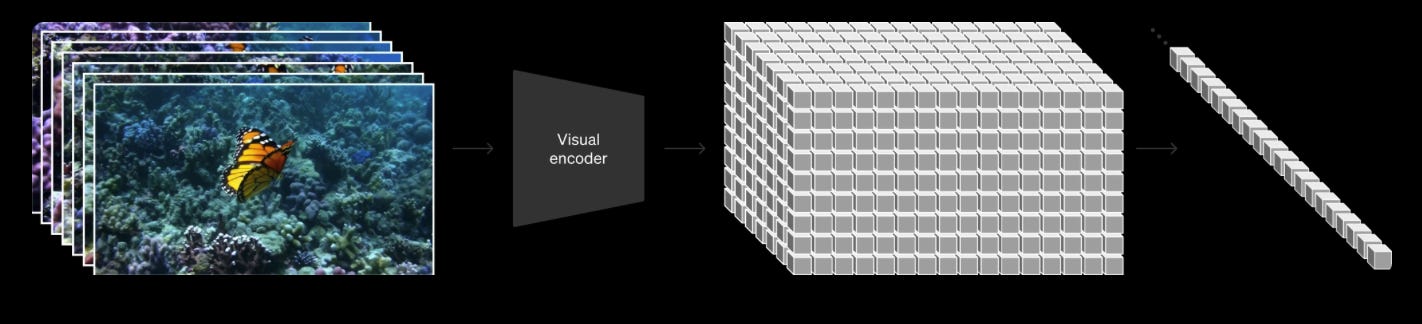
AI videos are made of individual frames of AI photos stitched together — though as we’ll see, they have to generate these frames together rather than one at a time. That’s why it’s nice to understand AI photos, first.
Modern AI image generators use a machine learning process called diffusion. Diffusion-based AI photo models are trained on images and “learn” how to predict what images should look like. We can compare them to Large Language Models to help our understanding.

I’ll summarize how diffusion-based image models work, but I’m not a machine learning expert. I work in media production and AI literacy. I’m pulling from my own generation experiences and fascination with AI. But if you’re interested in diving deeper, I recommend this video from Computerphile, a channel that covers a wide range of AI generation and AI safety topics. There are also more in-depth videos from channels like 3Blue1Brown and Welch Labs.
Diffusion models are trained on huge libraries of images. These images are scraped from the internet and come from licensed image libraries. Many of these photos come with captions or labels that people gave them online, but others will need to be captioned by AI systems or human annotators. This data is fed to a machine learning system (more on this later), which starts by encoding these images and accompanying text into a mathematical space. This is called “latent space,” which is a digital representation that stores the essence of the image. Latent space is where a lot of the “meaning” is embedded and associations can be discovered.
The model takes these latent representations and gradually adds noise to them over many steps (as seen in the cat image below). Its goal is to understand the entire path between clarity and pure static. Once it’s done that process billions of times, and often undergoes further tuning steps, you have a trained model!

If you want to generate an image with that model, give it a text prompt. The system starts with a field of random noise. It gradually denoises the image in steps, predicting what comes next based on the patterns it “learned” during training, and by the meaning of the text prompt. With each step it adds structure and detail, replacing the noise gradually, until at the end it’s resolved into something recognizable and detailed.
This is a very abstract process, and that process is evident in the image. Each prediction from one step of denoising to the next is an educated, mathematical guess. Sometimes guesses are wrong, and those mistakes can make visible artifacts. Early diffusion models struggled with hands or limbs, or weird symmetry and perspective. Newer versions are better, but even now, distortions and quirks pop up.
And it’s not just mistakes that you can see, but the generation process itself. Each AI model treats noise differently, and since its entire job is to denoise images, that means the results for one text prompt will yield different results in different models. Because noise is random, it will also yield different results from the same model. But different models often have their own “look” or “personality” that is distinct to their process.
A diffusion model is also quite flexible. You’re not limited to text prompts - you can guide them with images. You can train them to edit existing photos or generate them from scratch. They can blend multiple photos together. It’s an adaptable framework that can be scaled up or down.
Transformers
Real videos are sequences of real photos taken back-to-back, very quickly. So, if we want to make an AI video, can we just sequence individual AI photos back-to-back? Not quite.
In real life, where objects and people follow the laws of physics, we can take it for granted that sequential photos (frames) will show a consistent scene. But since AI photos are generated from scratch every time, and there’s a level of randomness with each photo, you need a way to chain AI frames together. Functionally, you have to generate all of the frames at once. For years, there wasn’t a good way to do this.
The transformer is probably the most consequential innovation in AI of the past decade. Modern AI models are extremely complex, and they need an architecture that organizes huge amounts of data and relationships. The transformer is a type of deep learning architecture that was introduced in 2017, and has since been applied widely.
Transformers have a core idea called “attention”, which is their ability to “look” at tons of data all at once and figure out how it all relates. With this ability, it can create higher-quality outputs. Transformers have great scaling properties, meaning that if they receive more data and more compute power they can improve drastically. This explains the massive amounts of compute power (and investment) needed for frontier AI models.
The GPT in ChatGPT stands for generative pre-trained transformer, which is OpenAI’s type of large language model. There were language models built on other learning architectures, but the transformer-based LLM was revolutionary.
Applying a transformer to images was a huge breakthrough in image generation. By combining a diffusion model with a transformer architecture you get… a diffusion transformer. It was introduced in late 2022 by Bill Peebles and Saining Xie. Recognizing the importance of the discovery, OpenAI hired Peebles shortly after, where he leads the Sora team to this day.
Diffusion Transformers break images into groups of pixels, which are turned into “patches.” Because transformers have an “attention” mechanism, AI video models could now pay “attention” not just to the patches in one frame or image, but also to how these patches change over time. This “time” attention layer can track changes and learn how things move. This is called “spatiotemporal attention”, and that’s as jargony as I will get. It allows AI to process multiple seconds of video at a time, building a consistent look and motion.
Like any transformer-based AI system, diffusion transformers are very scalable. This means they can improve with massive amounts of compute power and more training data. In other words, the diffusion transformer architecture is why AI images and videos have improved so much since 2023.
For example, the “Will Smith Eating Spaghetti” video was generated in 2023 by an AI architecture that was already on its way out. By 2025, diffusion transformer models like Veo 3 had found their footing.
Given the added complexity of generating videos, single frames of AI videos are more prone to errors and usually have less fidelity than individually-generated AI images. Even though the model tracks patches over time, it can still lose track of objects or “warp” them. Lighting and shadows can look unrealistic, and trying to get accurate sound is another tough task. And of course, even the most modern AI videos still have a “look.” Will that always be the case?
Why AI videos look like AI videos
So far, AI photo and video models have a visual fingerprint, even if it’s subtle. But if you think about it, that’s normal for real videos, too. A webcam on a computer looks different than a cinema camera, even though they’re both accurate representations of reality. So while AI videos may look real, they still carry a look from how they transform noise into structure and motion.
AI videos don’t have a real human capturing the video and responding to what’s happening. The camera is just an abstract viewpoint. That’s why an AI video of a baby trying to play with an outlet is unrealistic: a real person would put the phone down to help. A diffusion transformer doesn’t understand that like a human does.
But what about how realistic they look in general? Will they look “perfect” in just a few years? Let’s compare it to another generation method: video game engines.
Game engines and AI are structurally different, but both can try to generate a realistic scene. Unreal Engine can already simulate bespoke, photorealistic environments with few technical errors or “mistakes”. They already do this at incredible resolutions and frame rates. They even have near-perfect 3D assets of real physical objects, a virtual camera viewpoint, and they can mimic how real light works with ray tracing.
And yet, it still looks a bit synthetic somehow. Our feeds aren’t full of “video game slop”, even though it is readily accessible, and higher fidelity than AI video. That’s partially because making a new video game scene is hard, while AI videos are easy to make at a massive scale. But, I think we also underestimate how good we are at sensing what’s real.
Looking forward
If AI video still has room to grow, what determines how fast it improves? After 2023, AI companies started investing heavily in diffusion transformers. When a new, better AI video model comes out now, a lot of the improvements can be attributed to more investment and scale. But how fast they will keep improving is unclear.
An important factor I haven’t mentioned yet is that AI media generation is a sideshow compared to large language models, which have more direct economic upside for AI companies. AI models compete for resources. Companies like Anthropic, who focus on AI solutions for businesses, don’t even have an AI photo or video model. Companies like OpenAI and Google have photo and video models, but they’re usually announced at the end of their product presentations. Meanwhile, companies like Runway and Kling focus just on video generation and keep pushing ahead with new models. It’s not clear if any of these video or photo models are making any money.
At some point, the video scaling may slow down. We don’t know if or when this will happen, but it may become impractical to keep throwing more compute power and money at models to squeak out just a bit more quality. We’re not at that point yet. The AI video models will keep improving, and we’ll be keeping up with those updates as they come.