

AI Videos vs Deepfakes
They aren't the same, and it matters.


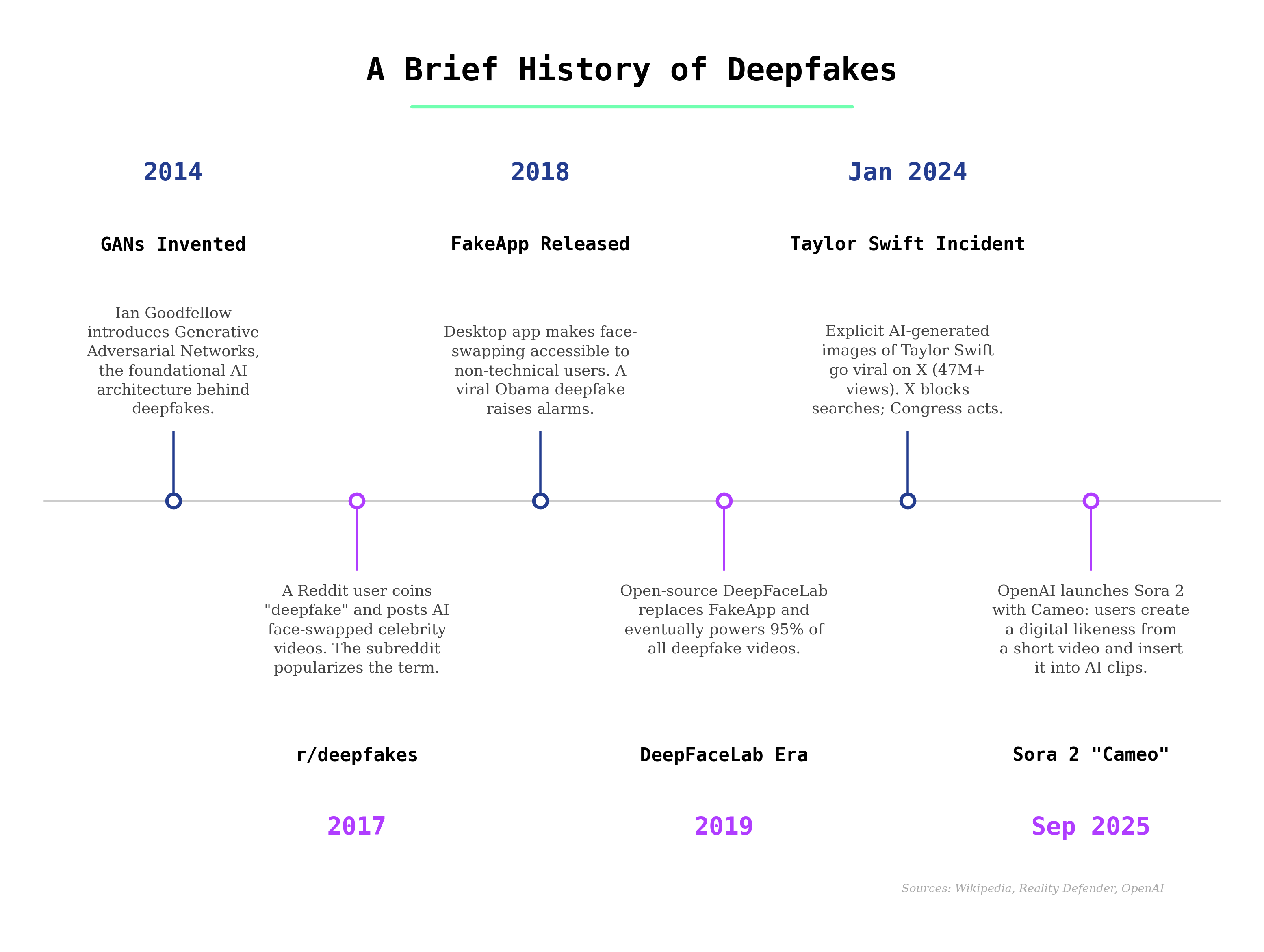
The word “deepfake” was coined in 2017 and is defined on Wikipedia as “images, videos, or audio that have been edited or generated using artificial intelligence, AI-based tools or audio-video editing software.”
At that time, deepfakes were the only AI videos out there. But now that wholly-AI-generated videos are everywhere, its definition might need some reworking.
If I tell a normal person to imagine an “AI video”, they probably think of AI bunnies on trampolines or some AI slop. But if I say “deepfake”, they probably think of politicians or public figures saying something they didn’t.
The public intuits that they’re different, so calling a deepfake an “AI video” can cause confusion. I’ll differentiate them so we can move forward with more clarity.
What is a deepfake?
A deepfake is a targeted manipulation of existing media, typically using machine learning tools. In most cases involving video, that means swapping someone’s face, so “face swapping” is nearly synonymous with “deepfake.” The body, movement, and background are usually real footage.
From the beginning, deepfakes were creating memes and nonconsensual pornography (covered in a 2018 article by Vice). A 2019 study by Deeptrace found that 96% of deepfake videos online were pornographic, and nearly all of them targeted women.
That hasn’t changed much. In January of 2024, deepfake images of Taylor Swift spread across X (covered in here on The Verge), attracting tens of millions of views before X shut them down. That incident became a flashpoint for legislation and awareness.
How deepfakes work
In my article “How AI videos work”, I covered how AI videos models use diffusion technology to generate entire videos from scratch. Most use an architecture that was introduced in December of 2022.
Deepfakes work differently. They use a machine learning technique that’s been around for much longer: the autoencoder.
An autoencoder has two parts: an encoder and a decoder. The encoder learns how to compress faces into compact mathematical sketches. It breaks features down into structures and expressions. The decoder learns how to rebuild the face from that sketch.
To swap faces, you train a shared encoder on two different people — let’s call them Person A and Person B — but give each person their own decoder. If you feed Person A’s video into Person B’s decoder, you get person B’s face making Person A’s expression. That’s a face swap, demonstrated here:
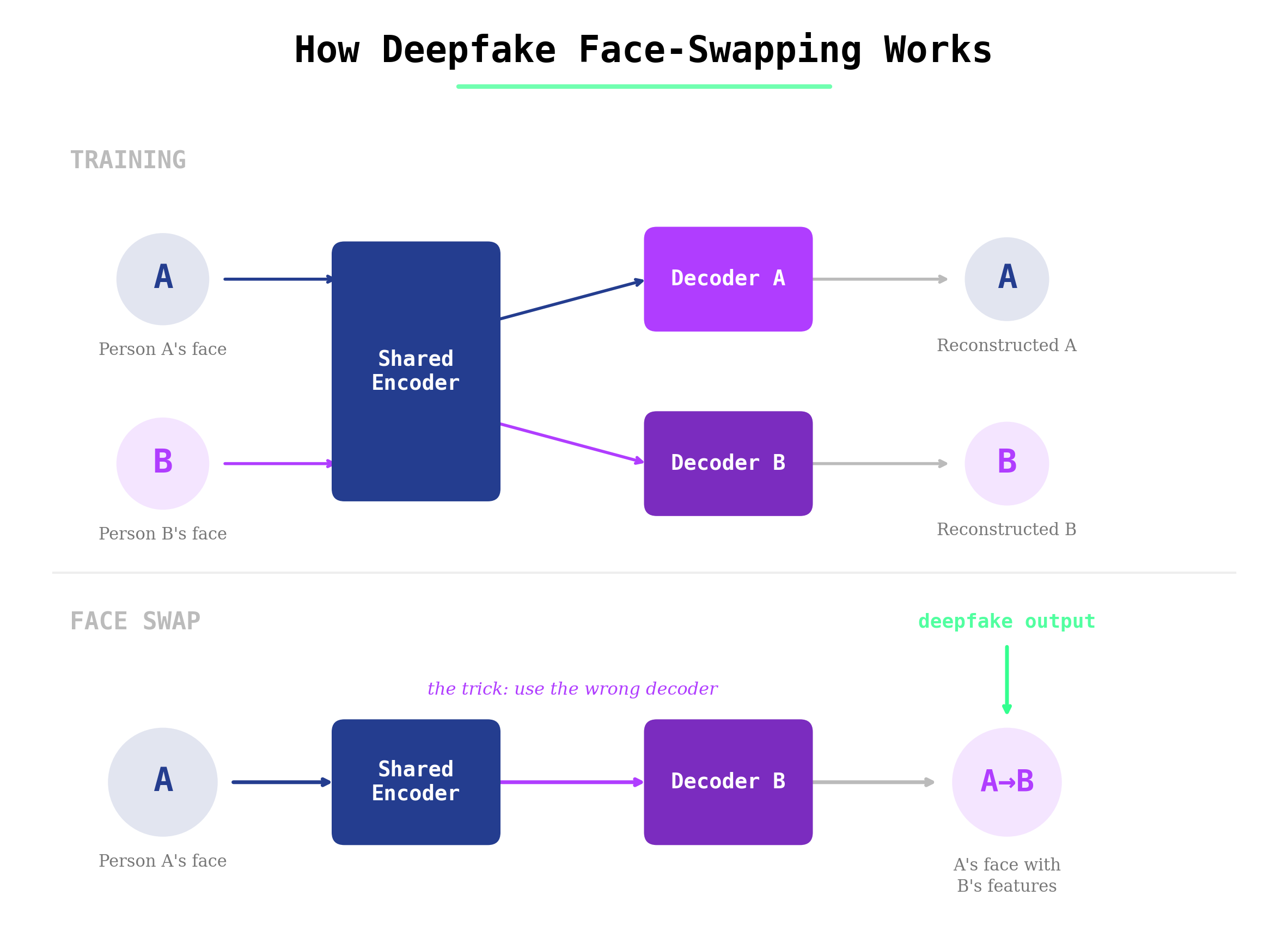
Some deepfakes also use general adversarial networks (GANs), which add a second AI into the mix. This “adversarial” network works to improve the quality by trying to catch the fake. The generator creates the fake face, and the discriminator evaluates whether it looks real. They push each other to improve, which is why GAN-based deepfakes can look very convincing.
The most popular deepfake tool was DeepFaceLab for a long time, but many commercial and open source projects have spun up in the past couple of years. These programs run on PCs with decent graphics cards. Each new deepfake is essentially a new AI model training on a new face. Training high-quality AI videos is done in huge data centers, instead, and that’s just one of the many differences.
The key differences between “AI videos”
Careful readers certainly noticed how many times the word “AI” showed up in the deepfakes explanation. There’s no question that it’s technically correct to call a deepfake an AI video.
But, autoencoders and GANs aren’t the AI systems most people think about when they hear “AI” anymore, and “AI video” conjures visions of a certain type of video.
The transformer architecture revolutionized the AI industry, proving to be the scalable base on which large language models and diffusion transformers have dominated. As a result, AI video models — like Sora, Runway, and Kling — work very differently from deepfakes. You give the model a text prompt, a reference image, or video, and it produces frames of video gradually by removing noise from random static, step by step, until a coherent scene emerges.
No parts of these AI-generated videos were ever real. The people, the backgrounds, the lighting, the movement, everything was entirely synthesized.
Detecting fake media
Let’s dive into how deepfakes and AI videos differ in their detection. Starting with visual detection, assuming it is a face-swapping deepfake, all of the tells are concentrated on the face or the face boundary. These include:
Blurry fringes, unnatural blending where the swapped face meets the skin or hair, or objects immediately around the face can show warping.
Resolution mismatches, where the face is a different sharpness or quality than the rest of the frame.
Lighting inconsistencies, where the face doesn’t match the scene’s light direction or color temperature.
Face tracking errors during fast movement. The face might lag, jitter, or briefly reveal the original face underneath.
On the contrary, AI video tells are distributed across the entire frame:
Dreamlike or impossible physics like objects passing through each other
Morphing, where objects, people, or backgrounds gradually change shape.
Broken or inconsistent text and signage.
Lighting and shadow weirdness that doesn’t correspond to any real light source.
Characteristic noise patterns, like Sora’s recognizable grain pattern or Veo’s smoother look.
But most importantly, detecting deepfakes is easier at scale. Automated AI video detection is still quite weak, and platform-side enforcement of AI video labeling is pretty relaxed. But there are scalable systems for removing deepfakes of notably figures because likeness detection is relatively simple. These systems need to be improved for less notable figures, like influencers and regular people, but the systems are there.
There are a two other major differences between AI videos and deepfakes:
Length and consistency
Deepfakes can be long. Since the base video is real, you can apply a face swap to an entire interview or speech. The swap just keeps up frame by frame. Longer deepfakes might have more errors, but they’re structurally simple.
AI videos are typically short. Most models still generate clips of around 10 seconds. Longer generations struggle with consistency and also are more expensive to generate, so they’re impractical.
Use cases and threats
Deepfakes have a specific threat profile. They’re primarily used for identity-based manipulation like political disinformation, and fraud, but the majority of deepfakes are still nonconsensual pornography targeting women.
AI videos have more applications, but the misinformation threat from AI videos is that they fabricate entire events that never happened at scale. Neither fake news broadcasts, nor staged disasters, nor fictional protests need real faces to be manipulative.
If only it were that simple
The technologies are starting to overlap.
The clearest example is Sora’s Cameo feature. Sora is an AI video model, so it generates videos from scratch. It lets you use your face, or someone else’s face if they have allowed it, to generate AI videos. It’s not technically a face swap (the video is still generated from scratch), but the result is still a realistic-looking video of a real person doing something they never did.
Some open-source AI models are also incorporating face reference features. And deepfake tools are starting to use newer AI architectures, including diffusion models, to improve their results.
But the convergence actually reinforces the need for linguistic separation. The general public was never keeping track of the underlying technologies. So moving forward, the language difference should be more about the threat and purpose of media, rather than the technology used.